



The emergence of voice assistants made the luxury of hands-free device control a daily reality. Whether you want to turn on the lights, ask a question, play music or place an online order, this technology is able both to respond to your command and anticipate your every need, significantly increasing the loyalty of users to your software.
In this article we’re shedding the light on how voice assistants work, how to implement each step as well give some tips on building an MVP for your own voice assistant.
What is Siri?
Siri is a built-in voice-controlled virtual assistant developed and maintained by Apple and incorporated in all the products in its ecosystem. The basic idea is to let users talk to the device to get the system to perform an action.
This personal assistant supports a wide range of commands, including
- sending texts and making phone calls or reminding of those
- setting reminders, alarms, scheduling events and assisting in other everyday tasks
- searching for music and playing the songs one wants
- running smart home appliances and creating triggers for certain actions (e.g. turning on the lights when the user gets home)
- handling device settings like adjusting display brightness or turning off Wi-Fi
- searching the Internet to check facts or answering questions the assistant already knows with pre-programmed responses
- making routes and analyzing traffic
- translating words and phrases from English to other languages
- doing calculations
- handling payments, etc.
Based on users routines, the system can make suggestions for what they might actually want by privately analyzing personal usage of different iOS applications. In other words, Siri does all the groundwork for you.
However, based on machine-learning technologies, voice assistants are the sum of several complex components. To understand how to develop one, it is worth exploring basic processes that stand behind this new technology to develop your own Siri-like voice product.
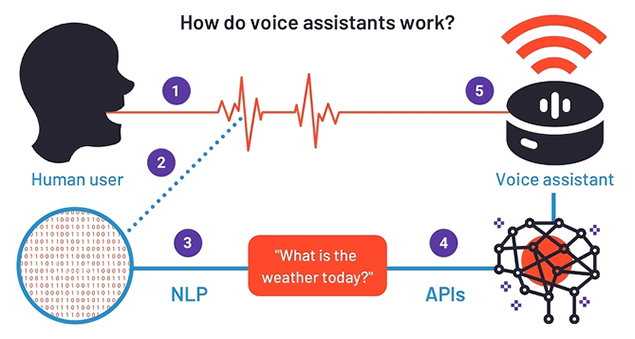
How do voice assistants work?
Once the voice assistant is activated and receives audio input, the voice recognition software launches a sequence of steps needed to process the data and generate appropriate response.
 Source: https://learn.g2.com
Source: https://learn.g2.com
To put it simply, the stages a typical voice assistant goes through are:
- speech recording coupled with noise reduction, (background sounds elimination), and identification of speech components that the machine is able to process;
- speech rendering into its textual representation based on extracted patterns;
- singling out most important words and the anticipated intent;
- asking specifying questions if needed;
- retrieving information by APIs calls to access a relevant knowledge base;
- information handling and fulfilling requested action.
The core of most of these steps lies within a natural language processing (NLP) technology, a subfield of computer science, information engineering, and artificial intelligence concerned with the ability of machines to recognize human speech and analyze its meaning.
Voice assistants mainly rely on natural language generation (NLG) and natural language understanding (NLU) as the parts of NLP. Obviously, NLU is responsible for accurate speech comprehension, while NLG transforms data into understandable to human ear parlance.
Based on this info, we can distinguish the major challenges any voice assistant deals with to become a working solution.
How to transform speech to text?
Voice assistants have to be able to distinguish between different accents, voice rates and pitches as well as abstract from any ambient sounds. After this, audio segmentation steps in to divide it into short consistent pieces that are later converted into text.
Much of this speech-to-text routine takes place on the servers and in the cloud, where your phone can access the corresponding database and software that analyze your speech. Since those remote servers are accessed by many people, the more it is used, the more knowledgeable the system gets.
Prior to any recognition process, the system should have an implemented acoustic model (AM) trained from a speech database and a linguistic model (LM) that determines the possible sequence of words/sentences. The data is handled to machine learning and server then compares the trained model with the input stream.
“The software breaks your speech down into tiny, recognizable parts called phonemes — there are only 44 of them in the English language. It’s the order, combination and context of these phonemes that allows the sophisticated audio analysis software to figure out what exactly you’re saying … For words that are pronounced the same way, such as eight and ate, the software analyzes the context and syntax of the sentence to figure out the best text match for the word you spoke. In its database, the software then matches the analyzed words with the text that best matches the words you spoke,”Scienceline says.
 Source: medium.com
Source: medium.com
For the system to transcribe your speech correctly, it should also be able to isolate the actual wording from any background sounds. This could be done both with hardware and software means. For instance, Siri uses Apple’s hardware. Yet, as long as noise reduction is based on algorithms, the process is first done with some software. After this stage, it is either moved to the hardware (if it is possible as in the case with Apple) or uses an OS preprocessor that removes rough noises (ex. baby cry, bark, clicks and similar sudden sounds).
For stationary noise - a random noise for which the probability that the noise voltage lies within any given interval does not change with time (ex. street, underground, trains) the procedure is different. Stationary noise is used to train an AM with the help of machine learning. Initially, it accumulates a solid noise-free database and is later added background sounds that are also included in the AM. This way, the system is able to recognize a human speech with stationary noise on the background without going through noise reduction stage.
How to describe text structure?
Machines can read, process and retrieve information from a text only when it is structured in a way that all the key elements are identified and classified into predefined categories. Such default categories may include names of persons, companies, places, time expressions, quantities, monetary value, percentages, etc. Words and phrases can also be assigned a certain grammatical role related to other text components, such as parent companies and their subsidiaries. This procedure of locating and labeling these elements is called entity extraction.
Text entity extraction enables the voice system to correlate words to their meanings and relevance within a sentence. It greatly contributes to the degree a voice assistant understands how the language works and to the ability of the system to trace certain sentence patterns to certain meanings.
How to identify the intent?
However, to interpret the exact meaning of users speech, it’s essential to identify the single intent - or aim - of the message. The challenge is that languages provide us with multiple ways to convey one and the same intent:
- What is the weather like today?
- Can you tell me whether I should put on my jacket?
- How cold will it in the evening?
Or imagine someone asks the voice assistant to tell about a certain city, what should the system extract as a real intent? Is this the latest city news, timetables, the weather forecast or something else pertaining to the name of the city? People rarely do say things explicitly, and may even omit the keywords. If the voice assistant is not able to recognize the intent, it won’t operate efficiently.
 Source: https://www.marketo.com
Source: https://www.marketo.com
One example of a successful intent abstraction is IBM DeepQA, a software architecture for deep content analysis and evidence-based reasoning. Here is how it works:
“First up, DeepQA works out what the question is asking, then works out some possible answers based on the information it has to hand, creating a thread for each. Every thread uses hundreds of algorithms to study the evidence, looking at factors including what the information says, what type of information it is, its reliability, and how likely it is to be relevant, then creating an individual weighting based on what Watson has previously learned about how likely they are to be right. It then generated a ranked list of answers, with evidence for each of its options.”
How to convert intent into action?
Finally, the intent should be translated into action to respond to the user’s request. Voice assistant like Siri have come a long way from answering trivial questions about the weather to controlling cars and smart home devices.
The process of impelling the system to perform a desired operation belongs to the OS level and is no different from those with tactile input.
How much would an MVP for a voice assistant cost?
There is one key rule for building a minimum viable product (MVP) for any voice initiative - start small and keep it simple. MVPs should include only those critical features that are needed for a product to function, yet demonstrate enough value for its earlier adopters.
We will use a driver’s voice assistant as an example and try to give you a rough idea of the costs associated with it. Note that we won’t be covering the hardware-related issues, such as porting to multiple platforms, noise dampening etc.
For an MVP you will need the voice assistant to react to about 20 most popular commands, e.g. “Voice assistant on”, “Navigate home”, “Find contact/location” etc. If your assistant is designed for the disabled people, you might need to prepare additional commands to accommodate their needs.
The first step would be to create suitable acoustic and linguistic models. To do this you should record at least a thousand people speaking the necessary commands. This number should include both men and women of varying ages and education levels. Creating a model would cost around 5000 USD.
The second step would require a team, including programmers, R&D specialists, QA engineers, and other professionals. They will create, test and train a deep neural network that would process the commands and act on them. We would estimate this part at around 20.000 USD.
Key takeaways
- Voice assistants like Siri focus on assisting users in their devices’ control.
- Natural language understanding (NLU) and natural language processing (NLP) and responsible for accurate speech recognition and correct data output.
- Before speech becomes a piece of text, it first goes through segmentation and analysis with the help of trained models.
- Text entity extraction is used to add structure to text by labeling its elements with certain meanings.
- For the system to determine the correct intent of the utterance, the text undergoes a complex weighting based the information type, its reliability, etc.
- After the desired action is identified, the system responds to it on the OS level in the same way as with tactile input.
- To develop an MVP choose a certain niche and train the system to respond to a set of the most basic commands.

Rate this article
Our Clients' Feedback













They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers (Israel)
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.

СEO at ElearningForce International (United States/Denmark)
Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.
Global Head of Commercial Development L&D at Technicolor