According to Gartner, in the upcoming years, enterprises will need more Gen AI models that are closely related to their industries. That means they will look for solutions to train their large language models (LLMs) and make them focus on proprietary knowledge. Data orchestration frameworks like LlamaIndex help build retrieval-augmented generation (RAG) systems and expand the possibilities of LLMs on top of specific organization’s data. LlamaIndex collects data from files (PDFs, PowerPoints), apps (Slack, Notion), and databases (MongoDB, Postgres) and structures it to make it easily digestible to LLMs.
Exploring Challenges with LLMs
LLMs have become the basis of the natural language generation (NLG) technology. They are used in chatbots, medical coding software, search engines, text summarization assistants, etc. They analyze written texts and generate new content. A trend towards “personalized” generative models comes from the demand for trustful content and compliance with security regulations. The recent launch of ChatGPT Gov for U.S. government agencies proves the tendency towards secure environments for handling sensitive information across industries.
Another trend is the appearance of agents that can support a natural conversation with a customer using up-to-date personalized data. For example, Amazon Bedrock Agents help design customer service chatbots that can process orders. Agents extend the functionality of the LLM by addressing third-party APIs and databases. As a result, they understand user requests, divide complex tasks into several steps, continue a conversation to learn more details, etc.
Experts mention several challenges associated with utilizing LLMs. Those challenges demonstrate the necessity of customizing language models to enterprise data.
- LLMs lack access to real-time information. They use the data that was relevant at the time when they were trained, so it does not include recent research, news, or tendencies. As a result, users may receive incorrect responses when they need to find out the latest information. After the appearance of ChatGPT in 2022, it became clear that the LLM underneath it was trained on the data of 2021 and was not able to give up-to-date answers to users’ queries. That is why Microsoft added the current information from the Web and introduced the Bing Chat. However, it was not yet focused on enterprise data.
- LLMs do not distinguish between facts and fiction. They may seem convincing, but the responses they generate appear misleading, especially when discussing specific domains. The cause of that lies also in the training data which may lack quality. In the context of health sciences, for example, incorrect data might even be dangerous for users.
- LLMs demonstrate false reasoning and impede the transparency of their functioning. It is difficult to understand how the system has come to this or that conclusion and which documented fact influenced the final response. Lack of information limits LLMs in solving logical problems. For example, research shows that puzzles such as riddles, programming puzzles, and logic games with missing information demand richer datasets to enhance LLM’s puzzle-solving capabilities.
- It is difficult for LLMs to discuss and memorize long documents. Despite the fact that context windows have become longer and LLMs are now able to process documents of up to 3,000 pages, there are drawbacks. LLMs fail to provide a grounded explanation of their output, they need more time to respond, and they demand higher costs, because of bigger input volumes.
Augmenting LLMs with RAG
RAG enables AI solutions to access and use the information of the enterprise. It comes from the name of this technology that it combines two components: a retriever and a generator. The system retrieves the information from indexed data sources (proprietary knowledge) and uses it to generate the response. As a result, the LLM integrates the knowledge of the organization with its generative capability.
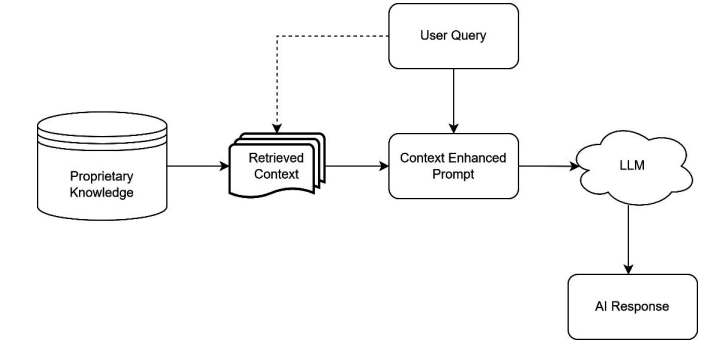
RAG allows LLMs to address the challenges mentioned above.
- RAG pulls the information from such sources as vector databases, relational databases, document-oriented databases, and file-based repositories. It allows LLMs to rely not only on its generative model’s knowledge but also on external up-to-date documents while providing responses. Thus, the information is real-time and the output is accurate.
- Due to retrieving the organization's proprietary knowledge, RAG technology allows for more truthful answers. Users are less likely to receive misleading information, as the system processes the context and facts related to the query.
- The retrieval component helps the RAG model find the data closely related to the query. This leads to better reasoning for the response. It is even possible for the users to get the actual quote from the source that the system referred to in its answer.
- RAG technology allows users to receive responses tailored to certain industries. For instance, healthcare LLM performs document analysis, customer and clinical decision support.
Is RAG the Only Possible Solution?
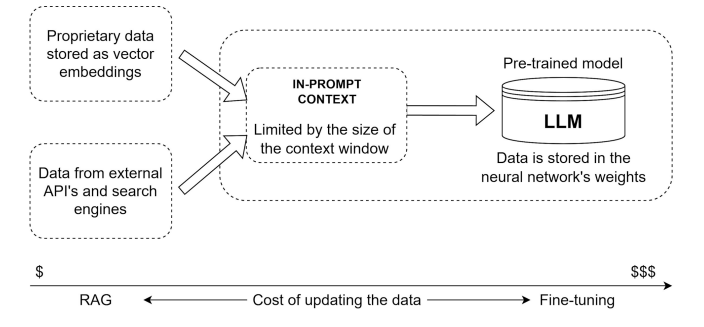
No, RAG is not the only one. Optimizing an LLM is also possible with prompting and fine-tuning.
Prompt engineering is changing requests to receive a more accurate response. It may be achieved by rephrasing queries, limiting ambiguity, giving more precise instructions, etc. It also demands that an engineer understand how the AI is going to interpret and run certain commands. This method is cheap, it is easy to implement and does not require additional datasets. However, prompt engineering is less effective in handling domain-specific requests. Besides, creating prompts takes much time, and long complex prompts may increase response times.
Fine-tuning AI models means training them additionally on proprietary data. After the pre-training on generic data, the model receives domain-specific data. It may be tailored to the set of tasks that this model should perform. For example, the LLM can be trained on internal branding guidelines, historical advertising campaigns, and instructions on the marketing tone of voice. After fine-tuning, this LLM will generate tailored ad banners and marketing posts that will adhere to the brand identity and tone.
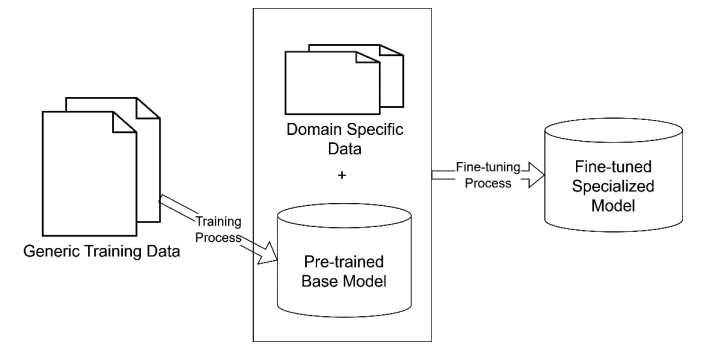
Among the disadvantages of fine-tuning are its high costs, demand for large datasets, and difficulties with updating the training dataset with fresh data. Another drawback is that fine-tuning may result in limiting the LLM to a certain domain and its worsened ability to handle requests outside this domain. For example, a model that is trained for medical coding won’t cope well with creative writing as it is focused on medical terminology. Sometimes, a model may also invent or overthink the facts. Thus, to the request “Who is the founder of the Belitsoft company?”, the model mentioned a fake person.
Low-Rank Adaptation (LoRA) may be seen as a solution to the mentioned drawback of a changed base AI model as a result of fine-tuning. LoRA does not affect all layers of the neural network. It fine-tunes only smaller matrices while leaving the larger pre-trained LLM unaltered. However, this approach needs significant computational resources and expertise.
RAG is often used in combination with fine-tuning. LlamaIndex is one of the ways to improve LLM-based applications using RAG. It is a framework that developers use to build custom RAG solutions. Let’s look closer at this framework.
Caidera.ai, a company dealing with marketing automation for the life sciences industry, faced high production costs and resource shortages. The integration of the company’s AI pipeline with LlamaIndex resulted in a 70% reduction in campaign creation time, doubled conversion rates, 40% less resources spent, and three times faster compliance processing. Belitsoft experts utilize LlamaIndex to train LLMs on internal data (docs, FAQs, knowledge bases, etc.).
What LlamaIndex Does
LlamaIndex is one of the tools for RAG, focused on indexing, connecting data sources, and feeding the right chunks of data into the LLM at query time.
With LlamaIndex, companies’ LLMs provide targeted and relevant responses on the basis of the business’s internal data. LlamaIndex organizes both structured and unstructured proprietary data into a retrievable format for further RAG workflows. The framework connects external datasets to popular LLMs like GPT-4, Claude, and Llama. As a result, businesses leverage the computational power of LLMs while focusing their responses on specific, reliable datasets, which maximizes the value of AI investments. LlamaIndex allows for the following possibilities:
- Build a search engine: LlamaIndex indexes many different formats, including Word files, PDFs, Notion documents, PowerPoint presentations, GitHub reports, etc.
- Create a customized chatbot: organizations “teach” their chatbots specific jargon and terminology, internal policies, and expertise to make them speak the language of their customers.
- Summarize large volumes of documents: companies like market research agencies can feed their LLMs reports on market trends, consumer behavior, and competitive analyses. Summaries of the key facts from those documents save analysts hours of manual work.
- Design an assistant: KPMG’s internal AI agents can retrieve, synthesize, and analyze enterprise data. Collaboration of LlamaIndex with Nvidia allows for developing a multi-agent system for conducting research and creating blog posts.
“In part to help fund LlamaCloud’s development, LlamaIndex recently raised $19 million in a Series A funding round that was led by Norwest Venture Partners, and saw participation from Greylock as well. The new cash brings LlamaIndex’s total funding raised to $27.5 million, and Liu says that it’ll be used for expanding LlamaIndex’s 20-person team and product development.” - TechCrunch
Progressive Disclosure of Complexity
This is the design principle that LlamIndex uses. It means the framework is accessible to developers of different levels of expertise. It is easy in the beginning, as you collect the data with a few lines of code. Further, more advanced features may be added if necessary. LlamaIndex immediately starts converting the data into indexes that are digestible to the LLM.
For example, to develop a company's knowledge assistant, advanced indexing technologies are used. First, developers load the necessary documents from a dataset. After that, they use the documents to create an index. It brings the system efficient querying and retrieval of information.
Developers can set up many parameters like selecting specialized index structures, optimizing indexes for different use cases, adapting to prompt strategies, and customizing query algorithms.
Important Aspects to Consider
Relying on third-party experts for custom LLMs guarantees the RAG workflows will be optimized correctly.
- The first step in RAG workflow is to organize and process proprietary data. It must be clean, without errors or duplicates. Redundant documents may confuse the RAG system. It is important to review and update the information, remove irrelevant data, and add new content. LlamaParse helps with the automatic processing of the data from different APIs, document types, and databases.
- Indexes may pose unexpected costs as they call LLMs to process large volumes of text. This may happen while building TreeIndex or KeywordTableIndex. The best solution is to stay informed of the potential expenses and to use indexes with no LLM calls (SummaryIndex, SimpleKeywordTableIndex) and cheaper LLMs. However, the latter may result in quality trade-offs. Caching and reusing indexes instead of rebuilding them also saves costs.
- To maintain data security, developers use local LLMs instead of hosted services.
How Belitsoft Can Help: Customizing and Deploying Your LlamaIndex Project
Belitsoft is a custom software development company offering full-cycle generative AI implementation services, including selecting AI model architecture (LLM vs. RAG), configuring infrastructure (on-premises vs. cloud), fine-tuning models with domain-specific data, integrating AI systems with organizational software, testing, and deployment.
By outsourcing Belitsoft's software developers, companies can create customized RAG applications tailored to their unique business needs. Belitsoft can set up RAG workflows on OpenAI models, as well as commercial and open-source models hosted locally to provide private options and reduce costs for large-scale projects.
Running an open-source LLM on customer hardware requires significant memory and computational resources. To address this, Belitsoft applies quantization, a post-training optimization technique that reduces memory usage and speeds up processing.
Belitsoft ensures the correct operation of RAG pipelines through careful evaluation. This process involves assessing retrieved nodes, output quality, scalability, and the ability to handle diverse queries, adversarial inputs, and edge cases.
If you're looking for expertise in LLM development services, custom LLM training, or AI chatbot development, we are ready to serve your needs. Contact us today and we will discuss your project requirements.

Rate this article
Recommended posts
.png)
.jpg)
.png)
.png)
.png)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
Our Clients' Feedback













Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.

Global Head of Commercial Development L&D at Technicolor
They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.
Founder from ZensAI (Microsoft)/ formerly Elearningforce