According to the results of the recent Gartner’s benchmarked survey “AI Strategy: Where Your Competitors Are Investing”, there is a growing number of companies that are planning to build out and deploy AI. A deep understanding of the main difference between the possibilities of AI software and “traditional” software can help to separate AI hype from reality.
Is AI considered Software?
"AI" (artificial intelligence) is the knowledge and techniques that enable machines to mimic humans' cognitive functions (learning, problem-solving, perception, and decision-making). But when you implement AI concepts into a program or application, that becomes AI software. For example, an application like a chatbot that uses NLP is AI software you can run, and interact with.
AI is like the theory, and AI software is the practical application of that theory. Just like how mathematics isn't software, but a calculator app (which uses mathematical algorithms) is software.
Even when we talk about AI models, those models are part of the software, but not standalone software by itself. A trained AI model is more like a file containing structured data, weights and other data in a format like .pt (PyTorch), which a program (AI software) loads and executes. The training process (which produces the model) is done before it becomes part of AI software. Once trained, a model is just a structured dataset that doesn't "run" by itself without AI software that loads and executes it.
AI can exist as a service (AIaaS), which is still software delivered via the cloud. But again, that's the software implementation of AI.
Comparison between Traditional Programming and Machine Learning (ML)
Machine Learning (ML) contrasts with traditional programming. While traditional programming relies on programmers to define explicit, scenario-specific logic and instructions, ML enables machines to learn autonomously and make decisions without detailed instructions for each task.
Comparison Using The Example of Marketing Automation in E-commerce
Traditional Programming
Standard programming techniques involve creating precise instructions. For example, for a common application, SQL queries are used to target specific demographic groups based on predefined criteria, such as age, purchase history, and gender. In this case, a marketer specifies the target audience, and the programmer manually crafts the necessary query.
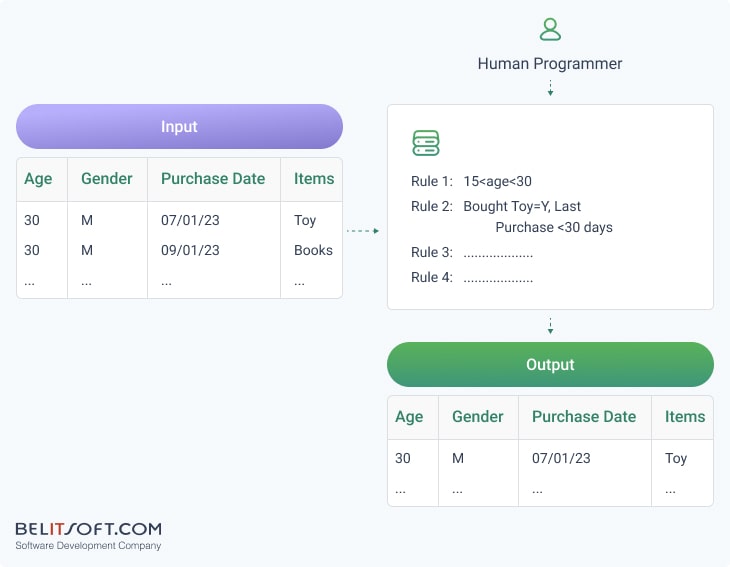
ML-Based Approach
ML changes the traditional approach by employing past data to train models and identify patterns. Once trained, these models can then predict outcomes on new, unseen data. For instance, ML models autonomously determine target customers for marketing campaigns, based on insights from data patterns. This simplifies the marketing process and reduces the need for manual targeting and segmentation programming.
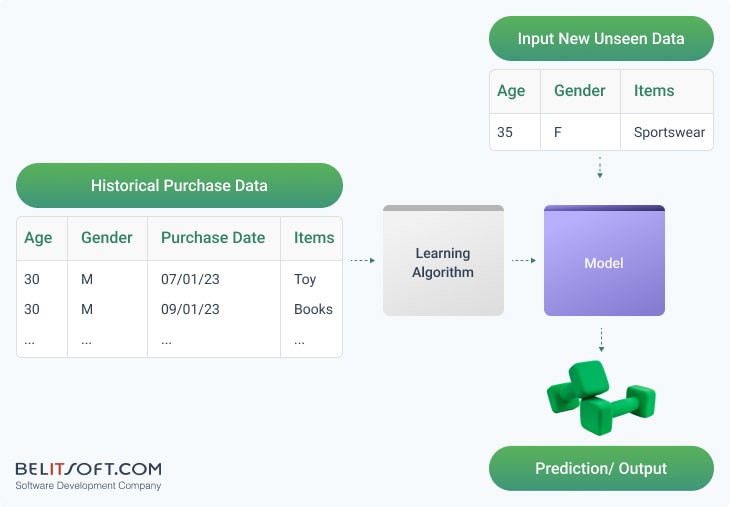
Advanced Segmentation with ML
Instead of manually segmenting audiences based on predetermined criteria, an ML model can analyze complex data patterns to identify new target groups. This process reveals insights that traditional analysis may overlook, potentially making the marketer's strategy more effective and less manual effort.
Necessity of Technical Expertise in ML
However, it's important to note that ML models still require initial programming, setup, and ongoing maintenance, often by data scientists or ML engineers. Collaboration between marketers and technical professionals is still necessary. Marketers provide input on campaign goals and parameters, while data professionals develop, train, and maintain the ML models.
ML's Superiority
Using machine learning in marketing has significant benefits, particularly in targeting strategies. ML algorithms can analyze large sets of data more efficiently and effectively than traditional methods. They can uncover complex patterns, trends, and customer behaviors that human analysts might miss. This leads to more precise and sophisticated audience segmentation.
Long-Term Benefits of ML
While ML models require initial resources, they can ultimately reduce the workload for marketers and programmers. Automated processes for data analysis and audience segmentation free up human resources for more strategic tasks. ML enables personalized marketing at a scale challenging to achieve manually. It tailors marketing messages and offers to specific segments based on customer preferences and behaviors, increasing marketing campaigns effectiveness.
In the long run, using ML can be more cost-effective. Refined targeting minimizes waste in marketing spend, as campaigns more accurately engage the intended audience. ML also provides a competitive edge. Companies that leverage advanced analytics and predictive modeling can often outperform competitors in terms of customer engagement and conversion rates.
Comparison Using The Example of Sales Predictions
Limitations of Traditional Predictive Software
While traditional software can make basic predictions based on historical data, its predictive capabilities are not as advanced as those of machine learning. For instance, traditional software might predict that if sales in January have been around $100,000 for the past few years, then the next January's sales will likely be similar. This form of prediction is a basic extrapolation, assuming that past patterns will repeat under similar conditions.
Advanced Pattern Recognition in ML
Machine learning, however, employs algorithms to identify complex patterns and relationships in data that are not immediately obvious or predictable through simple extrapolation. ML models adapt their predictions based on new data, continually refining their accuracy. An ML model predicting sales, for instance, might consider historical sales figures, changing customer preferences, market trends, economic conditions, and adjusts predictions with new data. Traditional rule-based systems lack this adaptability.
Data Processing: Traditional vs. ML Approaches
Both ML models and traditional software can access the same data, such as past sales figures, customer preferences, market trends, and economic conditions. The key difference lies in how they process and utilize this data. Traditional software operates based on explicit rules set by programmers. For example, a programmer might establish a rule like, "If past sales were X and the economic conditions are Y, predict sales to be Z." This approach is limited by the programmer's ability to anticipate and code for every potential scenario.
In contrast, ML models learn directly from the data. They autonomously detect complex patterns and relationships within the data, with no need for explicit programming for each scenario. ML algorithms can discover subtle correlations and trends that may not be evident or predictable in advance.
Adaptability of ML vs. Static Traditional Software
A significant difference is that traditional software does not adapt or learn independently. If market dynamics change or new trends emerge, the software will continue to operate based on its original programming until a programmer updates the rules. Meanwhile, ML models continuously update their understanding and predictions as new data arrives. This allows them to adapt to changes in patterns and trends without human intervention.
Probabilistic Nature of ML Models
However, there is a nuance with machine learning models not found in traditional programming. Unlike the deterministic outputs of traditional software, ML models provide probabilistic estimates. This means they predict the likelihood of various outcomes rather than offering absolute certainties. As such, continuous evaluation and potential retraining of these models are essential to maintain their accuracy.
Two types of ML: Supervised Versus Unsupervised Learning Models
Supervised Learning Model (Labeled Data)
Supervised Learning Applications
In supervised learning, models learn from data that has predefined labels, and algorithms must find structure and patterns in the data with guidance on what outcomes to predict.
Supervised learning is used in a wide range of applications, including but not limited to voice recognition (learning to understand and transcribe speech), and medical diagnosis (learning to identify diseases from symptoms and test results).
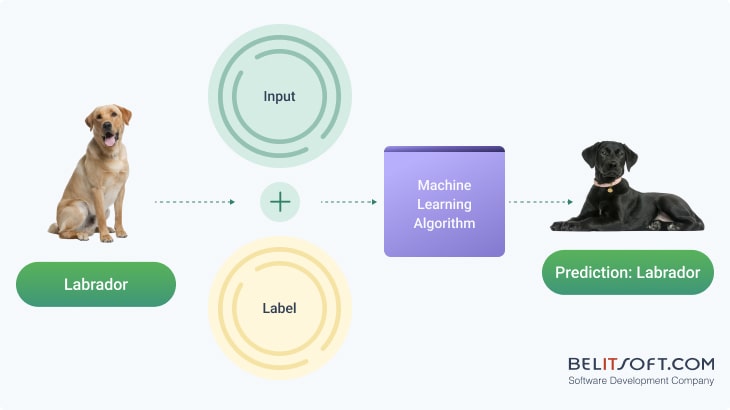
Let's use teaching a supervised machine learning model to identify dog breeds as an example
Preparing a Labeled Dataset
The first step is to collect a large dataset of dog images, labeling each image with the correct breed. For example, Golden Retrievers are labeled as "Golden Retriever," Poodles as "Poodle," and so on for each breed you want the model to recognize.
Feature Analysis and Training the Model
The model examines the features in each image, such as color patterns, ear shape, size, fur texture, and other physical characteristics distinctive to each breed.
During training, the model is fed these images and their corresponding breed labels. The model's task is to learn the patterns and characteristics indicative of each breed. For example, it may learn that Beagles often have a certain ear shape or that Huskies commonly have a specific fur texture.
Improving ML Accuracy
As the model goes through more images, it improves at recognizing and understanding the subtle differences between breeds. It adjusts its internal parameters to reduce prediction errors, like mistaking a Labrador for a Golden Retriever.
Recognizing dog breeds is more complex than simply identifying if an image contains a dog. Breeds can have subtle differences, and there's significant variation within each breed. Hence, the model needs to learn to focus on breed-specific characteristics while ignoring individual variances.
Testing the Trained Model on Unseen Data
After training, the model is tested with a set of images it hasn't seen before. For instance, if it has never seen a picture of a dog breed like a Dalmatian during training, it may struggle to identify a Dalmatian. The more diverse and comprehensive the training data (different breeds, colors, sizes, backgrounds), the better the model becomes at correctly identifying dog breeds. During the training phase, the model iteratively adjusts its parameters to minimize the difference between its predictions and the actual labels in the training data. This process is typically quantified using a loss function, which the model aims to minimize.
Some breeds may be harder to distinguish, requiring a larger or more diverse set of training images. Over time, adding more images and examples of difficult-to-distinguish breeds can improve the model's accuracy.
The quality of a supervised learning model depends heavily on the training data. Poor quality data can lead to issues like overfitting, underfitting, or biased predictions.
Unsupervised Learning Model (Unlabeled Data)
Applications and Advantages of Unsupervised Learning
Unsupervised learning is helpful in scenarios when we want to discover new patterns in data that were not previously considered. Common applications include market segmentation, anomaly detection, and organizing large datasets.
Unlike supervised learning, where models learn from data that has predefined labels, unsupervised learning algorithms work with data that has no labels. The algorithms must find structure and patterns in the data without guidance on predicting outcomes. The focus is on understanding the structure and distribution of the data.
Example of K-means Clustering
K-means Clustering is a classic example of an unsupervised learning algorithm. It partitions the data into 'k' distinct clusters. The algorithm assigns each data point to the nearest cluster. The goal is to minimize variance within each cluster and maximize variance between different clusters.
Feature-Based Clustering in Unsupervised Learning
Imagine, you possess a large collection of dog photos without breed labels. Your task is to organize these photos meaningfully without knowing the breed of each dog.
The unsupervised learning model analyzes photo features like dog size, fur length, ear shape, and color patterns without prior knowledge of dog breeds.
Pattern Recognition and Grouping in Unsupervised Learning
The model then tries to find patterns among these features. It might notice that some dogs have long fur and floppy ears, while others have short fur and pointy ears.
Based on these observed patterns, the model starts grouping the photos. Dogs with short fur and pointy ears might be grouped together, while those with long fur and floppy ears might be placed in a different group. The model measures the similarity of features to create these clusters.
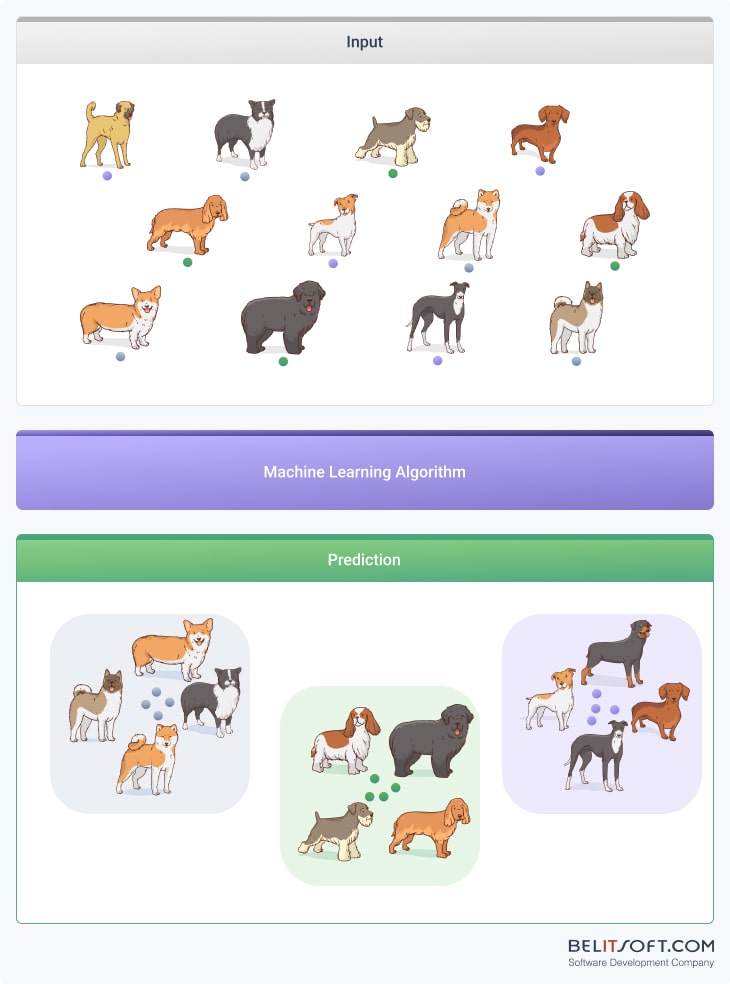
Each cluster represents a set of dogs that look similar. In an ideal scenario, these clusters might end up representing actual dog breeds, like one cluster having mostly Labrador Retrievers and another mostly German Shepherds. However, the model doesn't know the specific breeds; it only recognizes similar groups.
Dimensionality and Visualization in Data Clustering
Unsupervised learning models represent data points in two or three dimensions for visualization and easier comprehension.
For instance, in dog images, one axis might represent fur color, another the tail length, and so on. Data points close together are considered more similar and may belong to the same group or cluster.
High-Dimensional Data and Dimensionality Reduction Techniques
While data can have many dimensions (with each dimension representing a feature or characteristic of the data points), humans are best at visualizing in two or three dimensions. By plotting the data points based on these features, we can visually inspect the data. Data points that are similar will be closer together in this space, while different ones will be further apart. For example, images of a specific dog breed cluster together based on shared features like ear size and fur length.
In practice, data often has over 3 dimensions (high-dimensional), making direct visualization impossible. Techniques are used to reduce the number of dimensions while preserving as much of the significant structure in the data as possible.
As the observer, you can look at these clusters and recognize the breeds based on your knowledge. You can also adjust the criteria or the number of clusters (like determining the desired number of groups) to better match what you know about dog breeds.
Looking for AI solutions customized to meet the unique requirements of your business? Get in touch with us to find out how we can support your project.
You can't write the code for a car to navigate a roundabout, but AI can
Driving a car with software is impossible. You can't write the code with an if-then-else statement, case statement, or switch statement for a car to navigate a roundabout. But software can't train a car to drive. That's what AI does.
While conventional software is programmed to perform a task, AI is programmed to learn to perform the task.
Code is the primary artifact of “traditional” software. In AI software, code is not the primary artifact. Yes, when we build AI software we have to write code. But the primary artifact of AI is the data (data collection, data labeling, data analytics using algorithms to spot patterns).

Row Data Collection
The software cannot drive a car. But software can collect data. Cars have near-field sensors, microphones, cameras, lidar, and radar. And then AI just starts learning.
It learns how to make a right turn, how to make a left turn, how to go straight, how to recognize a stop sign, how to recognize a traffic light. Because of patterns, because it's got all this data. Once it sees a thousand stop signs, it can recognize a stop sign itself. That stop sign could be straight on. It can be cocked a bit, it can be bent, and it recognizes it because it's seen it enough times.
“The reason that cars can drive now and they couldn't drive themselves 10 years ago or 20 years ago is because of the cloud. The cloud changed the game with AI”
James A. Whittaker
The cloud changed the game because all that data that AI needs to learn takes a bit of storage.
You know, Google had a cloud, a proprietary cloud that did nothing but search. Amazon had a private proprietary cloud that did nothing but e-commerce. Facebook had a proprietary cloud that did nothing but store social data. This is where the modern AI was born - in these clouds. Alongside these technological giants, cloud migration companies have emerged to help various businesses and organizations leverage cloud capabilities.
You know, all that camera data from all those cars going through all those roundabouts takes a bit of storage! And the algorithm has to have access to it all. Before the cloud, it didn't.
Data labeling
Data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding meaningful labels to provide context so that a machine learning model can learn from it.
For example, you prepare 10 000 pictures of cats and label them "these pictures have cats". Then you prepare a bunch of pictures that don't have cats so they have the label "not a cat". And over time, the AI figures it out itself.
If you've ever taught a child to read letters, you show them the flashcards over and over. They guess it right, you're like "Hey, good job!" Guess it's wrong "No, you did wrong." We do the same thing with AI. We show it a bunch of examples, and when it gets it wrong, you change how data is labeled so it knows it got it wrong. It’s reinforcement learning.
“Let me make a prediction… Whereas programmers, developers in modern times are the most central to a team developing software, my prediction is data scientists are going to take over as the most important part of an AI project. Not coding. Because you have to recognize good data from bad data. You have to be able to label it correctly. Those labels help the algorithms to understand what's going on”
James A. Whittaker
Machine Learning Algorithms
You take your data, you label it, you organize it as well as a human can. And then you stick the algorithms on it.
Algorithms are used to analyze data, to gain insight, and to subsequently make a prediction or create a determination with it.
For example, look at the reinforced learning algorithm that provides recommendations for you on YouTube. After watching a video, the platform will show you similar titles that you believe you will like. But if you watch the recommendation and do not finish it, the machine understands that the recommendation would not be a good one and will try another approach next time.
Machine learning is a set of algorithms that enable the software to update itself and "learn" from previous outcomes with no programmer intervention.
In summary, a traditional algorithm takes some input and some logic as the code and drums up the output. As opposed to this, a Machine Learning Algorithm takes an input and an output and gives some logic, which can then work with new input to give one an output.
I think instead of universities studying the nuances of programming languages, we're going to be studying the nuances of algorithms… The nuances of data structures, how control structures work, whether to use an if-statement or a switch-statement or a lookup table are not going to matter. The skill that is going to matter is your understanding of probability statistics”
James A. Whittaker
Finding Patterns
A good data scientist can look at data and say, “That's probably the algorithm we should start with.” But that's the process: get the data and start running the algorithms through it and hope that those algorithms start finding patterns.
AI use cases fall into one or more of seven common patterns. The 7 patterns are hyper-personalization, autonomous systems, predictive analytics and decision support, conversational/human interactions, patterns and anomalies, recognition systems, and goal-driven systems.
For example, an algorithm can find such a pattern as “fraud/risk” demonstrating that things are out of the ordinary or expected.
“And this is a key skill that distinguishes a good Data Scientist from a mediocre Data Scientist. It's picking the right algorithms, understanding those patterns, and then iterating, combining algorithms to generate patterns”
James A. Whittaker
Feedback loop
Another fundamental difference between AI and conventional software is that software never changes. We build software, we release it to the field and it just does the same repeatedly. But once it gets out in the wild, it doesn't really change unless humans update it.
AI changes. An artificially intelligent car will go through a roundabout and it might discover something new. It might discover a car driving the wrong way on the roundabout. And once it figures out what to do - that's new data.
That's the thing about AI: it keeps learning even after it's released.
“The conventional software didn't wake up one day and said, "You know what? Fuck that shit. "I'm tired of processing those inputs. I'm gonna do something else.
James A. Whittaker“
That's not the way conventional software works. The AI software does work that way. AI software gets better itself.
The feedback loop is a cycle without an end:
- AI observes user actions and system events and captures data for analysis.
- AI analyzes this data against historical trends and data from other sources, if necessary.
- AI predicts outcomes and recommends specific actions.
- The loop starts over again. The system continues to refine its recommendations based on the latest feedback (whether the user accepted the recommendation and what happened after).
Rule-based chatbots vs AI chatbots
One illustrative example of the difference between traditional software and AI-driven software is the contrast between rule-based chatbots and AI chatbots—a distinction we're well-versed in, thanks to our extensive experience in custom chatbot development, both rule-based and AI-driven.
Rule-based chatbots work with simple instructions. They follow a script like, "If the user says 'A,' then reply with 'B.'" You'll find them handy for frequently asked questions or basic customer service tasks. Think of them as those voice-operated phone menus that guide you through a list of options. However, these bots have a big limitation: they don't learn or adapt. If a user asks something outside the script, the bot won't have an answer. This can make user interactions feel robotic and often frustrating, requiring ongoing tweaks from developers.
On the flip side, AI chatbots are a lot smarter. They use tech like machine learning and language understanding to figure out what users really want. Over time, they actually get better at helping people thanks to the data they collect. They can even notice patterns in questions from different users and refine their answers. These bots can handle multiple languages and tailor their responses to individual users. Plus, they know when a problem is too complex and a human needs to step in. That's why businesses that want more natural, intelligent interactions are going for AI bots.
Our example of Artificial Intelligence software in use today
As you see, the most important potential for AI is to be a recommendation engine.
Having solid experience in custom eLearning development, it is not surprising that our offshore software development company is looking for ways to implement AI in eLearning projects.
The core idea of AI in eLearning is the implementation of a Recommendation Engine on the eLearning platform. This tool recommends micro-learning content to the user based on their learning experience and other data that a user might provide (including search history or specific requests).
From the UI/UX perspective, it looks like an AI-powered chatbot or an AI-powered dashboard like YouTube or LinkedIn has.
Such chatbot assistants can automatically imitate tutors, understand the level of expertise of a learner, and pick information that is well fitted to a particular level.
For example, it can recommend skills to acquire for each learner and then match them with the corresponding courses.
That is just a small fraction of what we do. Recommendation Engine is developed to address a specific business need. It's hard to find a one-size-fits-all solution.
Enhance efficiency and customize operations with our AI software development services, designed for your specific data and business needs.

Rate this article
Recommended posts
.png)
.png)
.jpg)
.png)
.png)
.png)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
![Artificial Intelligence in Education [Ultimate Knowledge Hub]](/uploads/images/blog/posts/previews/image_163177848252-image(600x250-crop).jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
![How to Create a Language Learning App [The Ultimate Guide!]](/uploads/images/blog/posts/previews/image_155352483594-image(600x250-crop).png)
.jpg)
.jpg)
.jpg)
.jpg)
![Integrate Your CRM with LMS to Increase Sales [Start now!]](/uploads/images/blog/posts/previews/image_162030700147-image(600x250-crop).jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.png)
.jpg)
.jpg)
.jpg)
.png)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.png)
.png)
.png)
Our Clients' Feedback













Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.

Global Head of Commercial Development L&D at Technicolor
They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.
Founder from ZensAI (Microsoft)/ formerly Elearningforce