Researchers from MIT (The Massachusetts Institute of Technology) created a new artificial intelligence generating people's faces based on their voices. You probably think it’s impossible and straight out of science fiction, don’t you? But the developers have already demonstrated the outcomes of their work – the system draws actual portraits. Let's learn more about the idea.
What is Speech2Face?
Speech2Face (S2F) is a neural network or an AI algorithm trained to determine the gender, age, and ethnicity of a speaker by their voice. This system is also able to recreate an approximate portrait of a person from a speech sample.
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
How does Speech2Face work?
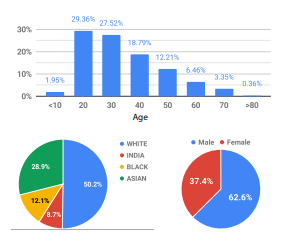
To train Speech2Face researchers used more than a million YouTube videos. Analyzing the images in the database, the system revealed typical correlations between facial traits and voices and learned to detect them.
S2F includes two main components:
- A voice encoder. As input, it takes a speech sample computed into a spectrogram - a visual representation of sound waves. Then the system encodes it into a vector with determined facial features.
- A face decoder. It takes the encoded vector and reconstructs the portrait from it. The image of the face is generated in standard form (front side and neutral by expression).
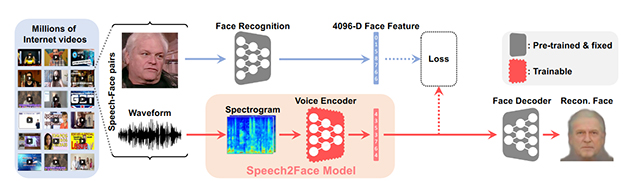 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Why does Speech2Face work?
MIT’s research team explains in detail why the idea of recreating a face just by voice works:
“There is a strong connection between speech and appearance, part of which is a direct result of the mechanics of speech production: age, gender (which affects the pitch of our voice), the shape of the mouth, facial bone structure, thin or full lips—all can affect the sound we generate”.
Testing and results assessment
Speech2Face was tested using qualitative and quantitative metrics. Scientists compared the traits of people in a video with their portraits created by voice. To evaluate the results researchers constructed a classification matrix.
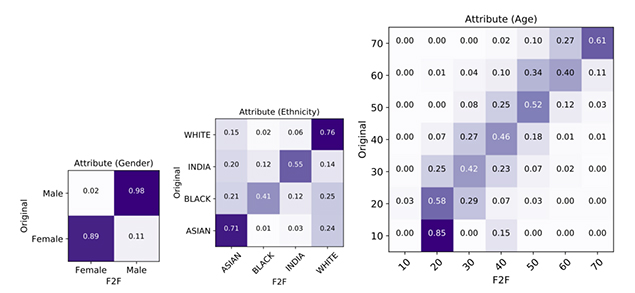 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Demographic attributes
It turned out that S2F copes successfully with pinpointing gender. However, it is far off determining age correctly and, on average, is mistaken for ± 10 years. Also, it was found that the algorithm recreates Europeans’ and Asians’ features best of all.
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Craniofacial attributes
Using a face attribute classifier, the researchers revealed that several craniofacial traits were reconstructed well. The best match was found for the nasal index and nose width.
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
The impact of input audio duration
The researchers decided to increase the length of voice recordings from 3 seconds to 6. This measure significantly improved the S2F reconstruction results, since the facial traits were captured better.
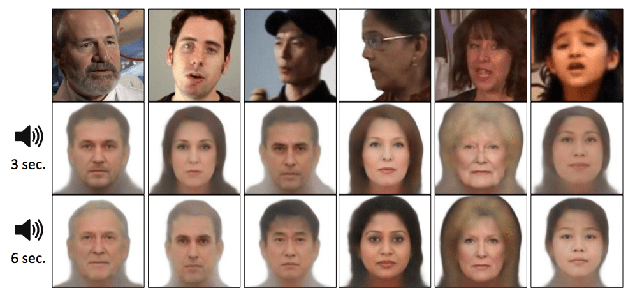 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Effect of language and accent
When S2F listened to an Asian male talking in English and Chinese, it reconstructed two different faces, one Asian and the second European. However, the neural network successfully identified an Asian girl speaking English and recreated a face with oriental features. So in case of language variations mixed performance was observed.
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Mismatches and Feature similarity
The researchers emphasize that S2F doesn’t reveal accurate representations of any individual but creates “average-looking faces.” So it can’t produce the persons’ image similar enough that you'd be able to recognize someone. MIT’s researchers give explanations to this:
“The goal was not to predict a recognizable image of the exact face, but rather to capture dominant facial traits of the person that are correlated with the input speech.”
Given that the system is still at the initial stage, it’s occasionally mistaken. Here are examples of some fails:
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Ethical questions
MIT’s researchers outspoken some ethical considerations about Speech2Face:
“The training data we use is a collection of educational videos from YouTube, and does not represent equally the entire world population … For example, if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language.”
So to enhance the Speech2Face results, researchers need to collect a complete database. It should represent people of different races, nationalities, levels of education, places of residence and therefore accents and languages.
Use Case - Speech-to-cartoon
S2F-made portraits could be used for creating personalized cartoons. For example, researchers did it with the help of GBoard app.
 Source: https://arxiv.org/pdf/1905.09773.pdf
Source: https://arxiv.org/pdf/1905.09773.pdf
Such cartoon-like faces can be used as a profile picture during a phone or video call. Especially, if a speaker prefers not to share a personal photo.
Also, animated faces can be directly assigned to voices used in virtual assistants and other smart home systems & devices.
Potential Use Cases
If the Spech2Face is trained further it could be useful for:
- Security forces and law enforcement agencies. Exact speech-to-face reconstructions can help to catch the criminals. For example, in the case of a masked bank robbery, phoned-in threats from terrorists or extortions from kidnappers.
- Media and motion picture industry. This technology can help VX (viewer experience) designers to build mind-blowing effects.
Conclusion
Presently Speech2Face appears to be an effective gender, age, and ethnicity classifier by voice. But this technology is also notable as it takes AI to another level. Perhaps, after further training, S2F will be able to predict the exact person’s face by voice. So it’s safe to say that we are witnessing a great breakthrough in the tech world and it’s exciting.

Rate this article
Recommended posts
.png)
.jpg)
.jpg)
.jpg)
.jpg)
![Artificial Intelligence in Education [Ultimate Knowledge Hub]](/uploads/images/blog/posts/previews/image_163177848252-image(600x250-crop).jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
![How to Create a Language Learning App [The Ultimate Guide!]](/uploads/images/blog/posts/previews/image_155352483594-image(600x250-crop).png)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
![Integrate Your CRM with LMS to Increase Sales [Start now!]](/uploads/images/blog/posts/previews/image_162030700147-image(600x250-crop).jpg)
.png)
.jpg)
.png)
.jpg)
.png)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.png)
.jpg)
.jpg)
.jpg)
.jpg)
.png)
Our Clients' Feedback













Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.

Global Head of Commercial Development L&D at Technicolor
They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.
Founder from ZensAI (Microsoft)/ formerly Elearningforce